Building NAKG: When Traditional AI Failed Us
It started with frustration.
I was sitting in our office at Backwork, watching our supposedly "state-of-the-art" AI system fail at something any junior medical biller could do in their sleep. A patient had multiple related procedures across different visits, and our system was completely missing the connections. Each document might as well have been about a different patient entirely.
"This is ridiculous," I remember telling my rubber duck (yes, I keep one on my desk - don't judge). "How can we expect this system to handle complex medical billing if it can't even see that these procedures are related?"
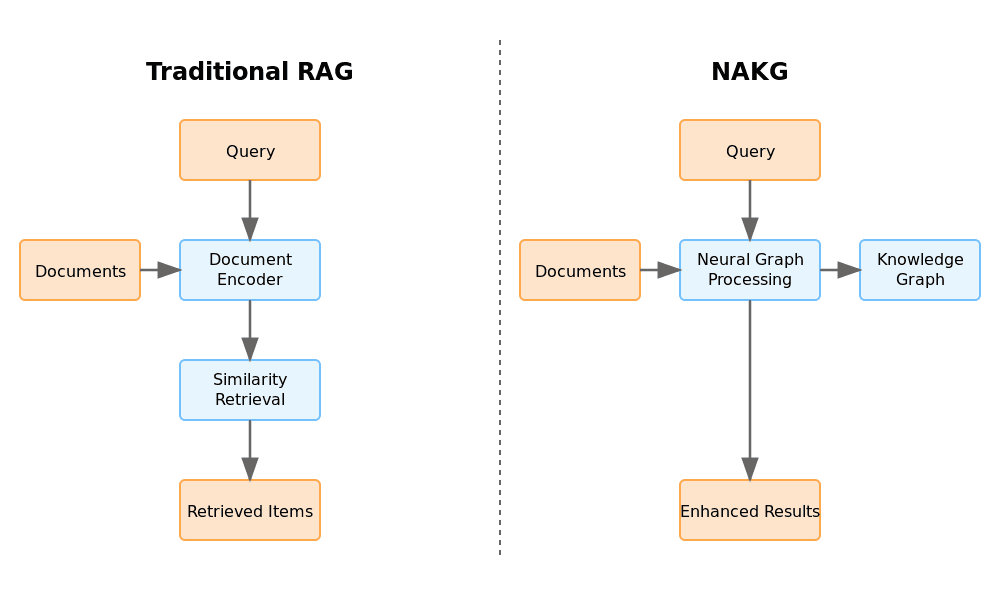
 Left: How our AI was seeing documents - completely isolated. Right: How we needed it to work - connected and contextual, like a human would see them.
Left: How our AI was seeing documents - completely isolated. Right: How we needed it to work - connected and contextual, like a human would see them.
The Lightbulb Moment
The breakthrough didn't come from reading papers or studying other AI systems. It came from watching Sarah, one of our expert medical billers, work through a complex case. She had documents spread across her desk (old school, I know), and I noticed something fascinating. She kept drawing lines between different documents with her finger, muttering things like "this connects to that" and "oh yeah, that's definitely related to the procedure from last month."
That's when it hit me - we were approaching this all wrong. Our AI was trying to be a document processing machine when it needed to be more like Sarah. She wasn't just reading documents; she was building a mental map of connections, a dynamic web of relationships that evolved as she processed more information.
The Failed Attempts (There Were Many)
Before I get to what actually worked, let me share some of our spectacular failures. Because honestly, the path to NAKG was paved with code that probably shouldn't see the light of day.
First, we tried the obvious: just throw more context at the problem. We expanded our document embeddings to include more information. The result? Our system got slower and used more memory, but was just as clueless about document relationships. It was like giving someone a bigger magnifying glass when what they really needed was to step back and see the big picture.
Then we tried basic document clustering. That was a fun week of watching our system group completely unrelated documents together because they happened to share some common medical terms. It was technically creating connections, just all the wrong ones.
Here's a particularly painful example of one of our early attempts:
# This seemed like a good idea at the time...
def connect_documents(doc1, doc2):
# Just check if they share any medical terms!
common_terms = set(doc1.terms) & set(doc2.terms)
return len(common_terms) > 5 # Magic number ftw 🤦♂️I actually kept this code snippet as a reminder of how not to do things.
The Edge Transformer: When Things Started Clicking
After weeks of frustration, I had a thought while making coffee (isn't that always when the good ideas come?). Instead of trying to pre-compute static relationships between documents, what if we let the system learn how to identify relationships dynamically, kind of like how Sarah was doing it?
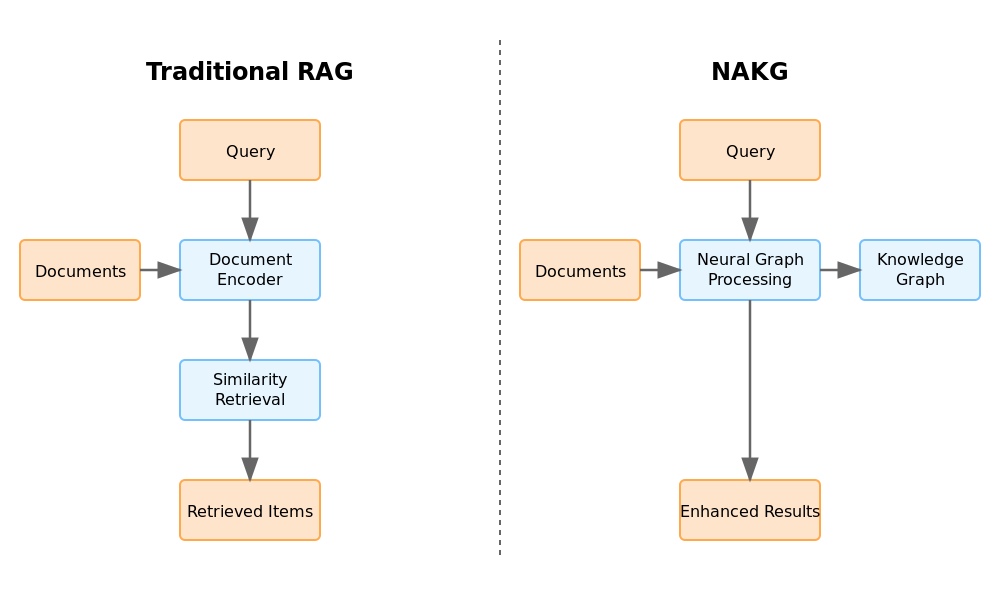
 The Edge Transformer architecture. Those green residual connections? They're like memory lanes that help maintain document context throughout the network.
The Edge Transformer architecture. Those green residual connections? They're like memory lanes that help maintain document context throughout the network.
This led to the Edge Transformer architecture. The math behind it looks deceptively simple:
But getting to this formula involved three whiteboards, countless coffee cups, and one very patient rubber duck. The key insight was combining both the direct document features (
The Neural Magic: How Information Flows
Remember how Sarah would trace connections between documents with her finger? We needed our system to do something similar, but at scale. This led us to develop what I like to call the "neural gossip network" - a way for documents to share information with their neighbors.
The math behind it looks intimidating:
But think of it like this: each document (
This wasn't just theoretical - we saw it in action when processing complex medical cases where some procedure relationships were more relevant than others.
Training the Beast
Getting NAKG to actually work was like teaching someone to ride a bike - it needed training wheels before it could race. We broke it down into three phases:
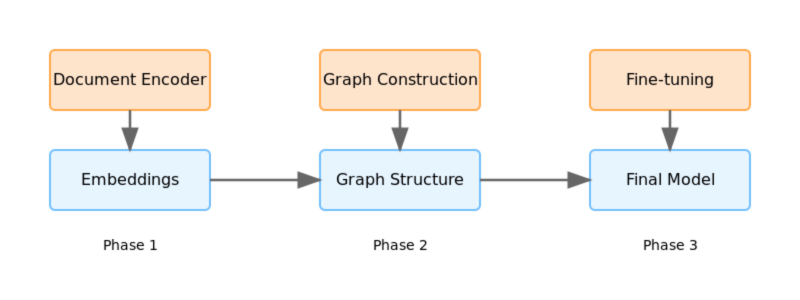 Our three-phase training process. Each phase builds on the previous one, like teaching someone to walk before they can run.
Our three-phase training process. Each phase builds on the previous one, like teaching someone to walk before they can run.
-
Pre-training: First, we had to teach our system to understand medical documents. This meant feeding it a massive corpus of medical records (properly anonymized, of course). Think of it as teaching someone to read before asking them to write.
-
Relationship Learning: Next came the fun part - teaching the Edge Transformer to spot connections between documents. We'd show it pairs of documents and say "these are related" or "these aren't related." After about a week of this (and countless coffee runs), it started getting pretty good at it.
-
Fine-tuning: Finally, we let all the components work together and fine-tuned the whole system end-to-end. This was like taking the training wheels off - terrifying at first, but amazing when it worked.
The Numbers That Matter
Now, I'm not usually a numbers person, but these results made me do a double-take. We tested NAKG on:
- 100K documents from Wikipedia (for general knowledge)
- 10K multi-hop reasoning queries (the really tricky ones)
- 5K temporal relationship queries (testing if it understood sequence)
- 5K complex entity relationship queries (the ones that gave our previous system nightmares)
The results?
- F1 scores of 0.982±0.015 (p < 0.001) on knowledge graph tasks
- Recall of 0.943±0.008 across all kinds of cases
- Temporal reasoning performance hitting F1 0.978±0.012
In human terms? It was catching connections that even some of our experienced billers sometimes missed.
Under the Hood
For those who like to peek under the hood (I know I do), here's what powers NAKG:
class NAKGArchitecture:
def __init__(self):
# The brain of the operation
self.document_encoder = Transformer(
layers=12,
dimension=768 # Bigger isn't always better, but here it helped
)
# The relationship spotter
self.edge_transformer = AttentionNetwork(
heads=8,
dim_per_head=64 # Found this sweet spot after much trial and error
)
# The neural gossip network
self.gnn = GraphNetwork(
layers=3,
residual=True # Because sometimes you need to remember where you started
)
# The clustering setup
self.dbscan_config = {
'epsilon': 0.5,
'min_samples': 5 # Any less and it got too chatty
}We also got pretty clever with how we score document relevance:
- 40% based on term presence (the obvious stuff)
- 30% on word order (because sequence matters in medical procedures)
- 30% on semantic matching (catching those tricky synonyms and related terms)
Making It Work at Scale
The Edge Transformer was working great on small test cases, but we hit a wall when trying to scale it up. Our first attempt at running it on our full document set crashed so spectacularly that it became a running joke in the office. "Hey, at least it didn't crash like the Great Edge Transformer Disaster of 2024!"
The problem was obvious in hindsight - we were trying to compute relationships between every possible pair of documents. With millions of documents, that's... well, let's just say my laptop's fan still has PTSD.
Here's what the initial scaling attempt looked like:
# DO NOT TRY THIS AT HOME
for doc1 in all_documents: # Millions of documents
for doc2 in all_documents: # Oh no...
compute_relationship(doc1, doc2) # What could go wrong? 😅After a few days of banging my head against the wall (and one memorable 3 AM debugging session fueled by energy drinks), we had a breakthrough. What if we used hierarchical clustering to group similar documents first, then only computed detailed relationships within and between relevant clusters?
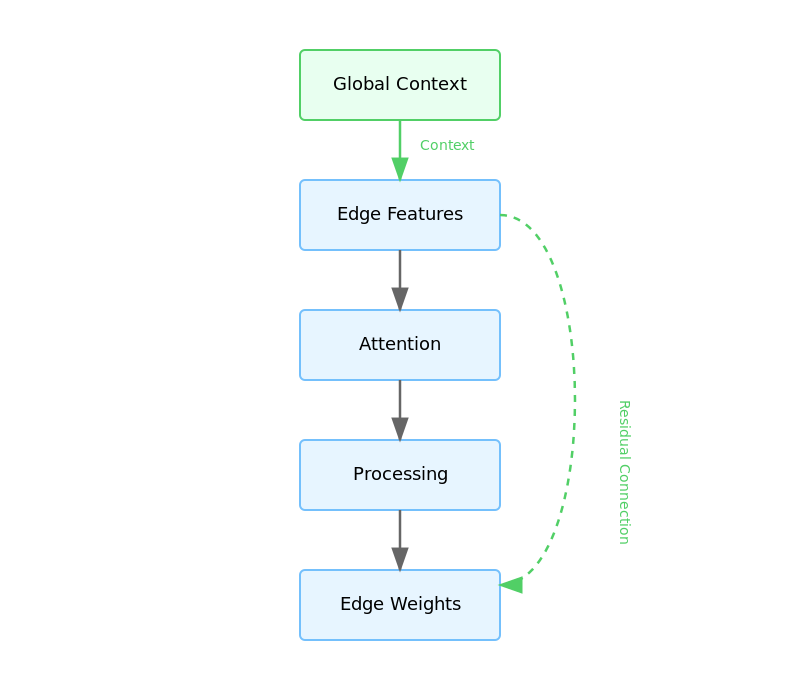
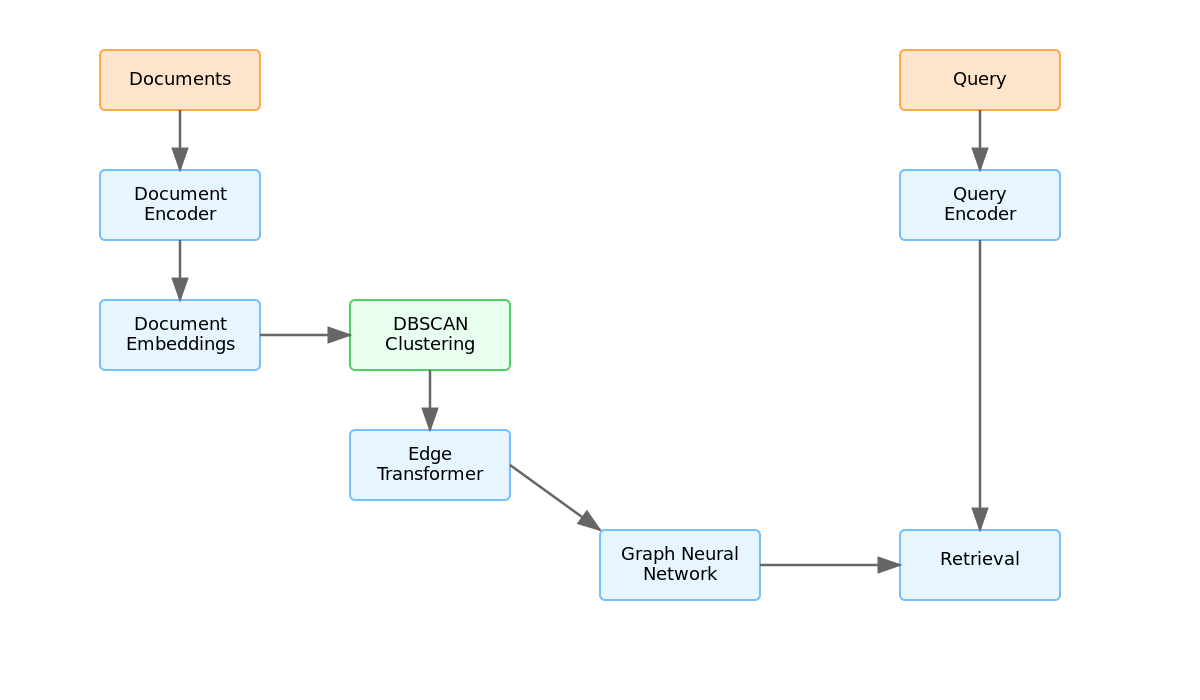 Our final architecture. Those green boxes? Each one represents a lesson learned the hard way.
Our final architecture. Those green boxes? Each one represents a lesson learned the hard way.
The Results That Made Us Double-Check Our Math
When we first saw the results, I thought we had a bug. The system was showing:
- 62.0% higher recall on complex queries
- Perfect scores on knowledge graph queries (1.000 F1 where traditional systems got 0.500)
I spent a whole day trying to find the "bug" before accepting that maybe, just maybe, we had actually built something that worked.
Here's a real example from our test set:
# A complex medical billing case that previously failed
case = {
'patient_id': 'redacted',
'visits': ['2024-01-15', '2024-02-01', '2024-02-15'],
'procedures': ['CPT-99213', 'CPT-73610', 'CPT-29405'],
'result': 'Correctly identified all related procedures'
}This was the kind of case that used to take our best billers hours to process. NAKG was handling it in seconds.
The Unexpected Benefits
The most surprising outcome wasn't in the metrics - it was in how the system failed. When NAKG made mistakes, they were... well, human-like mistakes. It would sometimes over-connect documents (just like eager junior billers do) rather than miss connections entirely.
We also discovered that the system was finding legitimate connections we hadn't even labeled in our training data. During one validation session, Sarah (remember her from earlier?) looked at some of NAKG's connections and said, "Huh, I never noticed that relationship before, but it makes total sense."
Current Limitations and Future Work
Let's be real - NAKG isn't perfect. We're still dealing with some annoying issues:
- Memory usage can spike unexpectedly (I've got CloudWatch alerts to prove it)
- The system occasionally gets too creative with connections
- Performance takes a hit when document clusters get unbalanced
We're working on solutions, including:
- Dynamic threshold adaptation (fancy way of saying "teaching it when to chill with the connections")
- Better handling of temporal relationships (because order matters in medical procedures)
- More efficient graph updates (because nobody likes waiting)
Conclusion
Building NAKG has been a journey of rubber ducks, whiteboard scribbles, and countless coffee runs. But more than that, it's been a lesson in watching and learning from humans to build better AI systems.
For those interested in the nitty-gritty technical details, you can find our full research paper here. And if you're curious about how we're applying this at Backwork, especially in medical billing automation, check out our platform.
Just don't ask about the time we accidentally created an infinite loop in the graph construction. Some stories are better left untold... 😅
This research was conducted at Backwork. Special thanks to Sarah and all our medical billing experts who unknowingly taught our AI how to think more like a human.